3 Структуры и модели данных
Структура данных – организационная схема данных, в соответствии с которой они упорядочены, с тем, чтобы их можно было интерпретировать и выполнять над ними определенные операции.
В отношении структур данных различают два понятия: физическая и логическая структура данных.
Понятие "физическая структура данных" отражает способ физического представления данных в памяти машины и называется еще структурой хранения, внутренней структурой или структурой памяти.
Рассмотрение структуры данных без учета ее представления в машинной памяти называется абстрактной или логической структурой. В общем случае между логической и соответствующей ей физической структурами существует различие.
В памяти компьютера данные могут иметь последовательное или связанное представление. Соответственно различают структуры хранения, использующие последовательное представление данных и связанное представление данных.
При последовательном представлении данные в памяти компьютера размещаются в соседних последовательно расположенных ячейках. При этом физический порядок следования записей полностью соответствует логическому порядку, определяемому логической структурой, то есть логическая структура поддерживается физическим порядком следования данных. Совокупность записей, размещенных в последовательно расположенных ячейках памяти, называют последовательным списком.

Рисунок 3.1 - Представление в памяти записи в виде последовательности полей
При связанном представлении в каждой записи предусматривается дополнительное поле, в котором размещается указатель (ссылка). В памяти компьютера записи располагаются в любых свободных ячейках и связываются между собой указателями, указывающими на место расположения записи, логически следующей за данной. Структуры хранения, основанные на связанном представлении данных, называют связанными списками. Если каждая запись содержит лишь один указатель, то список односвязный, при большем числе указателей - список многосвязный.

Рисунок 3.2 - Структура односвязного списка

Рисунок 3.3 - Структура двухсвязного списка
Структуры данных могут быть однородными и неоднородными.
В однородных структурах все элементы данных представлены записями одного и того же типа.
В неоднородных - элементами одной структуры могут являться записи разных типов.
Пример неоднородной записи - совокупность сведений о некотором студенте.
Объект "студент" обладает свойствами:
- "личный номер" - характеризуется целым положительным числом;
- "фамилия-имя-отчество" - характеризуется строкой символов и т.д.
Пример: var rec:record num :byte; { личный номер студента }name :string[20]; { Ф.И.О. }
fac, group:string[7]; { факультет, группа }
math,comp,lang :byte; {оценки по мат-ке, выч. технике, ин.яз.}
end;
Различные структуры данных предоставляют и различный доступ к своим элементам: в одних структурах доступ возможен к любому элементу, в других - к строго определенному.
Важный признак структуры данных - характер упорядоченности ее элементов. По этому признаку структуры можно делить на линейные и нелинейные структуры.
К линейным структурам относят массив, стек, очередь, таблица.
Массив – линейная структура данных фиксированного размера, реализуемая с использованием последовательного представления данных. Каждый элемент массива идентифицируется одним или несколькими индексами. Индекс – это целое число, значение которого определяет позицию соответствующего элемента в массиве и используется для осуществления доступа к этому элементу. Отдельные элементы массива могут изменяться, но общее число элементов массива остается неизменным. (Для массива не реализуются операции удаления и добавления, только модификации). В зависимости от числа индексов различают одно мерные и многомерные массивы.
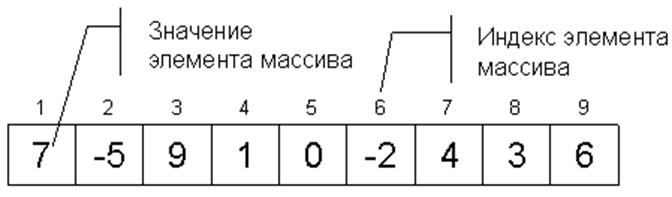
Рисунок 3.4 – Одномерный массив
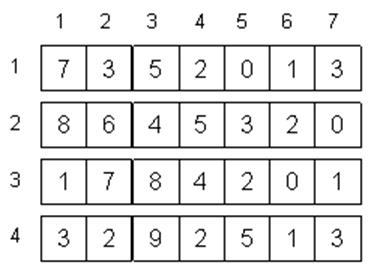
Рисунок 3.5 – Двумерный массив
Стек – линейная структура переменного размера, позволяющая включать и исключать элементы. Доступ к элементам для включения и исключения возможны только с одного конца структуры – с вершины (информация обрабатывается по принципу «последним пришел – первым ушел»). Для хранения стека может использоваться как последовательное, так и связное представление.

Рисунок 3.6 - Стек
Очередь – линейная структура данных переменного размера. Исключение элементов из очереди допускается только с одного конца – с начала очереди. Включение элементов возможно лишь в конец очереди. Данные обрабатываются по принципу «первым пришел – первым ушел». Доступ к элементам осуществляется по указателям начала и конца. Для реализации очереди может использоваться как последовательное, так и связное представление.
![]()
Рисунок 3.7 - Очередь
Таблица – линейная структура данных, каждый элемент которой характеризуется определенным значением ключа и доступ к элементам которой осуществляется по ключу. По ключу осуществляется и включение и исключение элементов структуры. Для реализации таблицы может использоваться как последовательное, так и связное представление. Обычно таблицы упорядочивают по какому-либо принципу (например, по возрастанию/убыванию значений ключа).

Рисунок 3.8 – Таблица
В нелинейных структурах связь между элементами структуры (записями) определяется отношениями подчинения или какими-либо логическими условиями. К нелинейным структурам принадлежат деревья, графы, многосвязные списки и списковые структуры.
Отношения между объектами реального мира часто носят нелинейный характер. Это могут быть отношения, определяемые логическими условиями, отношениями типа "один-ко-многим" или "многие-ко-многим". Отношения "один-ко-многим" носят иерархический характер и отображаются древовидными структурами. В виде иерархии может быть представлена например, структура учебных подразделений ВУЗа.
Отношения "многие-ко-многим" носят более универсальный характер и отображаются структурами графов. Пример такого отношения. Каждый ВУЗ распределяет своих выпускников на различные предприятия. В то же время предприятие поучает специалистов из различных ВУЗов.
Граф общего вида состоит из ряда вершин (узлов) и ребер, связывающих пары вершин. Если в понятия "ребро" и "вершина" вложить определенную смысловую нагрузку, то графы можно использовать для представления данных. Так вершинам графа можно сопоставить определенные объекты, тогда ребра будут соответствовать отношениям между объектами. В литературе по структурам баз данных модель данных, имеющую вид ориентированного графа, называют сетью.
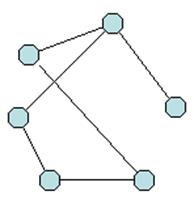
Рисунок 3.9 - Граф
Дерево представляет собой граф с некоторыми ограничениями, то есть это ориентированный граф, не имеющий циклов. Вершины (узлы) дерева организованы по уровням, то есть, подчинены определенной иерархии. Любой узел дерева связан с единственным узлом более высокого уровня - порождающим - и с m узлами ближайшего уровня - порожденными. На самом верхнем уровне, в начале дерева имеется единственный узел, называемый корнем. Узлы, расположенные в конце каждой ветви дерева и не имеющие порожденных, называются листьями. В деревьях направление обязательно от порождающего к порожденному. Количество уровней дерева определяет высоту дерева. Древовидные структуры данных более удобны для реализации в памяти компьютера, чем сетевые. При обработке древовидных структур наиболее типичной является операция обхода - процедура, при выполнении которой каждый узел обрабатывается ровно один раз. Способы обхода (нисходящий, восходящий, смешанный) отличаются точкой входа в дерево, направлением движения по дереву. Структуры деревьев могут реализовываться в памяти компьютера с использованием как последовательного, так и связанного представления данных.

Рисунок 3.10 - Дерево
Структура данных, в которой любой элемент может сам являться списком, называется списковой. Примером может служить список, отображающий процесс разборки автомобиля. Сначала автомобиль разбирается на основные агрегаты; агрегаты последовательно делятся на узлы, которые, в сою очередь, можно разобрать на отдельные детали. Списковую структуру можно изобразить в виде графа. Для представления в памяти компьютера списковые структуры требуют связанного представления.
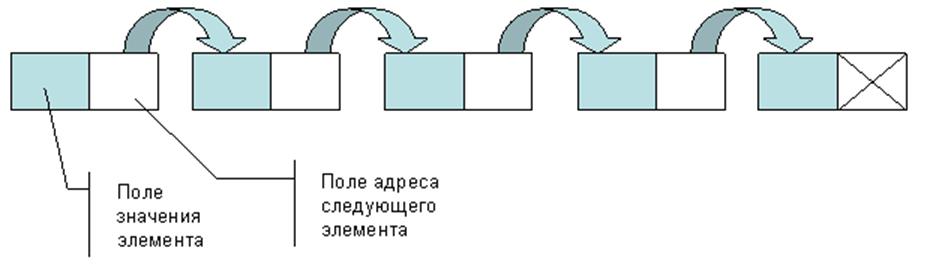
Рисунок 3.11 – Линейный список
При разработке структур данных всех уровней должен обеспечиваться принцип независимости от данных. Независимость данных - возможность изменения логической и физической структуры БД без изменения представлений пользователей.
Физическая независимость от данных означает, что любые изменения в физическом расположении данных или техническом обеспечении БД не должны отражаться на логических структурах и прикладных программах, то есть не должны вызывать в них изменений. [Такие изменения внутренней (физической) схемы данных как переход на новую файловую систему, другое устройство хранения, изменение индексов или способа хэширования, должны осуществляться без необходимости внесения изменений на логическом уровне]. Пользователи могут заметить изменения только за счет изменения общей производительности системы.
Логическая независимость от данных означает, что изменения в структурах хранения не должны вызывать изменения в логических структурах данных и в прикладных программах. Такие изменения, как добавление или удаление новых объектов (таблиц БД), атрибутов или связей, должны осуществляться без необходимости внесения изменений в уже существующие схемы или корректировки прикладных программ. Пользователи, для которых эти изменения предназначались, должны о них знать, но важно, чтобы другие пользователи даже и не подозревали о них.
Соблюдение принципа независимости данных позволяет использовать особые виды данных: виртуальные и прозрачные.
Виртуальные данные существуют лишь на логическом уровне. Пользователю эти данные представляются реально существующими, и он оперирует ими при необходимости. Каждый раз при обращении к этим данным система определенным образом их генерирует на основании других данных, физически существующих в системе.
Прозрачные данные представляются несуществующими на логическом уровне. Это позволяет скрыть от пользователя многие сложные механизмы, используемые при преобразовании логических структур данных в физические (примером могут служить индексы).
3.1 Модели данных
Модель данных — это совокупность концепций, используемых для описания структуры набора данных, связей между ними и ограничений, накладываемых на данные в некоторой организации.
Любая модель данных содержит три компоненты:
1. структурная - описывает точку зрения пользователя на форму представление данных или набор правил, по которым может быть построена база данных;
2. манипуляционная – определяет набор допустимых операций, выполняемых на структуре данных. Это компонент предполагает, как минимум, наличие языка определения данных (ЯОД), описывающего структуру хранения данных, и языка манипулирования данными (ЯМД), включающего операции извлечения и модификации (вставка, удаление, изменение) данных;
3. целостная - механизм поддержания соответствия данных предметной области на основе формально описанных правил или набор ограничений поддержки целостности данных, гарантирующих корректность используемых данных.
В процессе исторического развития в СУБД использовались следующие модели данных:
- реляционная;
- иерархическая;
- сетевая.
Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных:
- постреляционная;
- многомерная;
- объектно-ориентированная.
Иерархическая модель позволяет строить БД с иерархической древовидной структурой и состоит из объектов с указателями от родительских объектов к потомкам, соединяя вместе связанную информацию.
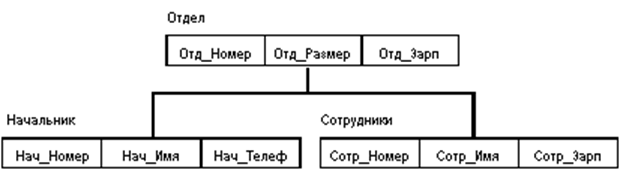
Рисунок 3.12 – Пример схемы иерархической БД
К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя.
На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.
Сетевая модель позволяет организовывать БД, структура которых представляется графом общего вида. Вершинам графа соответствуют некоторые типы сущности (объекты), которые представляются таблицами, а дугам соответствуют типы связей.
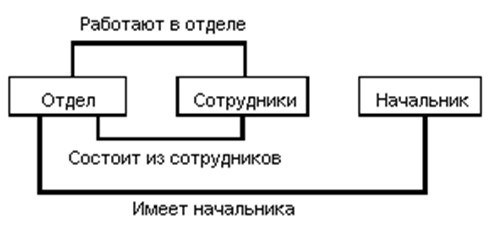
Рисунок 3.13 – Простой пример сетевой схемы БД
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db VistaIII, СЕТЬ, СЕТОР и КОМПАС.
В основе реляционной модели лежит понятие отношения (плоская таблица), представляющего собой подмножество декартова произведения доменов.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Существует ряд случаев, когда это ограничение мешает эффективной реализации приложений.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля - поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
Примеры постреляционных СУБД: uniVers, Bubba, Dasdb
На рисунке 3.14 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Таблица Накладные содержит данные о номерах накладных и кодах покупателей. В таблице Движение товара содержатся данные о каждой из накладных: номер накладной, название товара и количество товара. Таблица Накладные связана с таблицей Движение товара по полю номер накладной.
|
Накладные |
|
|
№_ТТН |
Код-покупателя |
|
0373 |
8723 |
|
8374 |
8232 |
|
7364 |
8723 |
|
Движение товара |
||
|
№_ТТН |
Товар |
Кол-во |
|
0373 |
Сыр |
3 |
|
0373 |
Рыба |
2 |
|
8374 |
Лимонад |
1 |
|
8374 |
Сок |
6 |
|
8374 |
Печенье |
2 |
|
7364 |
Йогурт |
1 |
а)
|
Накладные |
|||
|
№_ТТН |
Код-покупателя |
Товар |
Кол-во |
|
0373 |
8723 |
Сыр |
3 |
|
0373 |
|
Рыба |
2 |
|
8374 |
8232 |
Лимонад |
1 |
|
8374 |
|
Сок |
6 |
|
8374 |
|
Печенье |
2 |
|
7364 |
8723 |
Йогурт |
1 |
б)
Рисунок 3.14 – Пример реляционной (а) и постреляционной (б) моделей данных
Как видно из рисунка, по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц.
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеют большую гибкость.
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, то возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах.
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
Многомерная модель. Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
Основными понятиями многомерной модели данных являются:
- гиперкуб данных (Data Hypercube);
- измерение (Dimension);
- метки (Memders);
- ячейка (Cell);
- мера (Measure).
Гиперкуб данных содержит одно или более измерений и представляет собой упорядоченный набор ячеек. Каждая ячейка определяется одним и только одним набором значений измерений - меток. Ячейка может содержать данные - меру или быть пустой.
Под измерением будем понимать множество меток, образующих одну из граней гиперкуба. Примером временного измерения является список дней, месяцев, кварталов. Примером географического измерения может быть перечень территориальных объектов: населенных пунктов, районов, регионов, стран и т.д.
Для получения доступа к данным пользователю необходимо указать одну или несколько ячеек путем выбора значений измерений, которым соответствуют необходимые ячейки. Процесс выбора значений измерений будем называть фиксацией меток, а множества выбранных значений измерений - множеством фиксированных меток.
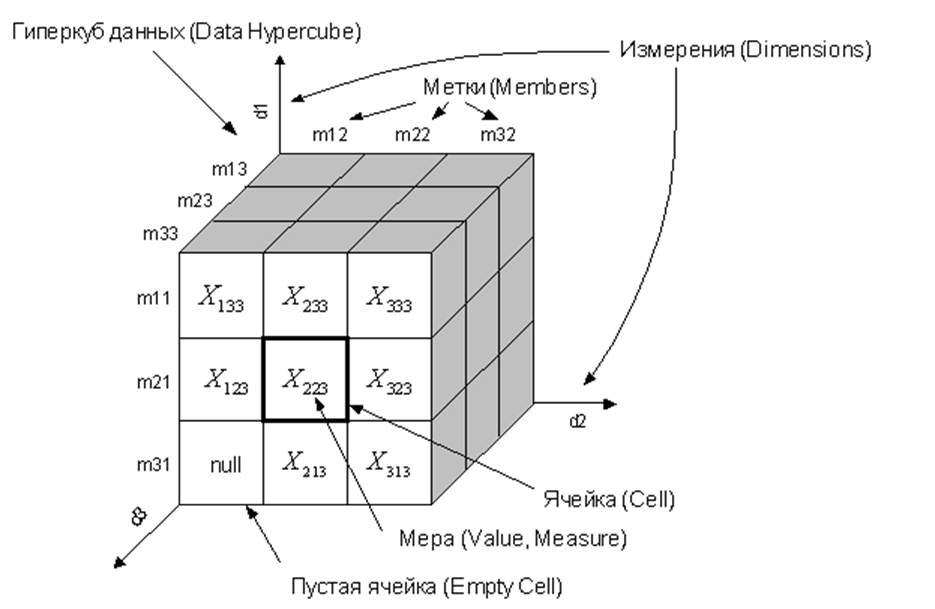
Рисунок 3.15 – Гиперкуб данных
По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью.
Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию.
Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примерами систем, поддерживающими многомерные модели данных, являются Cache, Teradata, Essbase (Arbor Software), Media Multi-matrix (Speedware), Oracle Express Server (Oracle) и Cache (InterSystems). Некоторые программные продукты, например Media/ MR (Speedware), позволяют одновременно работать с многомерными и с реляционными БД. В СУБД Cache, в которой внутренней моделью данных является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
Объектно-ориентированная модель. В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты.
Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма. Ограниченно могут применяться операции, подобные командам SQL (например, для создания БД).
Создание и модификация БД сопровождается автоматическим формированием и последующей корректировкой индексов (индексных таблиц), содержащих информацию для быстрого поиска данных.
Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД.
Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложных связях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
В настоящее время такие системы получили широкое распространение, в частности, к ним относятся следующие СУБД: РОЕТ (РОЕТ Software), Jasmine (Computer Associates), Versant (Versant Technologies), 02 (Ardent Software), ODB-Jupiter (научно-производственный центр "Интелтек Плюс"), а также Iris, Orion и Postgres.