Лекция 1. Введение в программирование и язык C++, Переменные, типы данных, ввод/вывод
Компьютеры понимают только очень ограниченный набор инструкций, и чтобы заставить их что-то делать, нужно четко сформулировать задание, используя эти же инструкции. Программа (также «приложение» или «программное обеспечение», или «софт») — это набор инструкций, которые указывают компьютеру, что ему нужно делать. Физическая часть компьютера, которая выполняет эти инструкции, называется «железом» или аппаратной частью (например, процессор, материнская плата и т.д.). Данный урок является началом серии уроков по программированию на языке С++ для начинающих.
Машинный язык
Процессор компьютера не способен понимать напрямую языки программирования, такие как C++, Java, Python и т.д. Очень ограниченный набор инструкций, которые изначально понимает процессор, называется машинным кодом (или «машинным языком»). То, как эти инструкции организованы, выходит за рамки данного введения, но стоит отметить две вещи.
Во-первых, каждая команда (инструкция) состоит только из определенной последовательности (набора) цифр: 0 и 1. Эти числа называются битами (сокр. от «binary digit») или двоичным кодом.
Например, одна команда машинного кода архитектуры ×86 выглядит следующим образом:
10110000 01100001
Во-вторых, каждый набор бит переводится процессором в инструкции для выполнения определенного задания (например, сравнить два числа или переместить число в определенную ячейку памяти). Разные типы процессоров обычно имеют разные наборы инструкций, поэтому инструкции, которые будут работать на процессорах Intel (используются в персональных компьютерах), с большей долей вероятности, не будут работать на процессорах Xenon (используются в игровых приставках Xbox). Раньше, когда компьютеры только начинали массово распространяться, программисты должны были писать программы непосредственно на машинном языке, что было очень неудобно, сложно и занимало намного больше времени, чем сейчас.
Язык ассемблера
Так как программировать на машинном языке — удовольствие специфическое, то программисты изобрели язык ассемблера. В этом языке каждая команда идентифицируется коротким именем (а не набором единиц с нулями), и переменными можно управлять через их имена. Таким образом, писать/читать код стало гораздо легче. Тем не менее, процессор все равно не понимает язык ассемблера напрямую. Его также нужно переводить, с помощью ассемблера, в машинный код. Ассемблер — это транслятор (переводчик), который переводит код, написанный на языке ассемблера, в машинный язык. В Интернете язык ассемблера часто называют просто «Ассемблер».
Преимуществом Ассемблера является его производительность (точнее скорость выполнения) и он до сих пор используется, когда это имеет решающее значение. Тем не менее, причина подобного преимущества заключается в том, что программирование на этом языке адаптируется к конкретному процессору. Программы, адаптированные под один процессор, не будут работать с другим. Кроме того, чтобы программировать на Ассемблере, по-прежнему нужно знать очень много не очень читабельных инструкций для выполнения даже простого задания.
Например, вот вышеприведенная команда, но уже на языке ассемблера:
Высокоуровневые языки программирования
Для решения проблем читабельности кода и чрезмерной сложности были разработаны высокоуровневые языки программирования. C, C++, Pascal, Java, JavaScript и Perl — это всё языки высокого уровня. Они позволяют писать и выполнять программы, не переживая о совместимости кода с разными архитектурами процессоров. Программы, написанные на языках высокого уровня, также должны быть переведены в машинный код перед выполнением. Есть два варианта:
компиляция, которая выполняется компилятором;
интерпретация, которая выполняется интерпретатором.
Компилятор — это программа, которая читает код и создает автономную (способную работать независимо от другого аппаратного или программного обеспечения) исполняемую программу, которую процессор понимает напрямую. При запуске программы весь код компилируется целиком, а затем создается исполняемый файл и уже при повторном запуске программы компиляция не выполняется.
Проще говоря, процесс компиляции выглядит следующим образом:
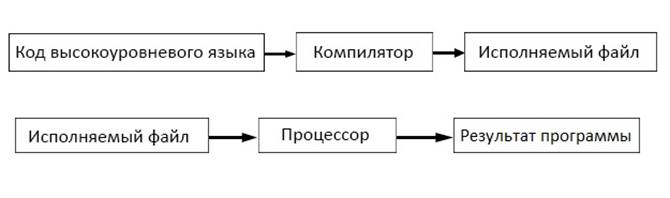
Интерпретатор — это программа, которая напрямую выполняет код, без его предыдущей компиляции в исполняемый файл. Интерпретаторы более гибкие, но менее эффективные, так как процесс интерпретации выполняется повторно при каждом запуске программы.
Процесс интерпретации:

Любой язык программирования может быть компилируемым или интерпретируемым, однако, такие языки, как C, C++ и Pascal — компилируются, в то время как «скриптовые» языки, такие, как Perl и JavaScript — интерпретируются. Некоторые языки программирования (например, Java) могут как компилироваться, так и интерпретироваться.
Преимущества высокоуровневых языков программирования
Преимущество №1: Легче писать/читать код. Вот вышеприведенная команда, но уже на языке C++:
а = 97;
Преимущество №2: Требуется меньше инструкций для выполнения определенного задания. В языке C++ вы можете сделать что-то вроде а = Ь * 2 + 5; в одной строке. В языке ассемблера вам пришлось бы использовать 5 или 6 инструкций.
Преимущество №3: Вы не должны заботиться о таких деталях, как загрузка переменных в регистры процессора. Компилятор или интерпретатор берёт это на себя.
Преимущество №4: Высокоуровневые языки программирования более портируемые под различные архитектуры (но есть один нюанс).
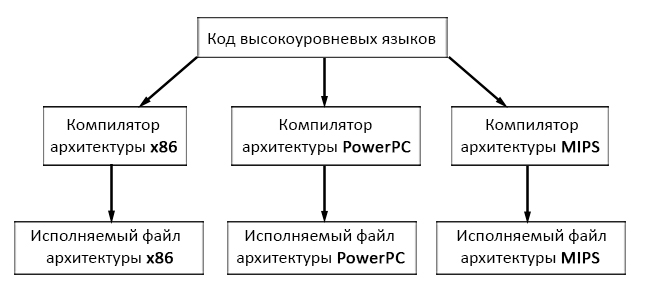
Нюанс заключается в том, что многие платформы, такие как Microsoft Windows, имеют свои собственные специфические функции, с помощью которых писать код намного легче. Но в таком случае приходится жертвовать портируемостью, так как функции, специфические для одной платформы, с большей долей вероятности, не будут работать на другой платформе.
Структура программ С++
Cтейтмент (англ. «statement») — это наиболее распространенный тип инструкций в программах. Это и есть та самая инструкция, наименьшая независимая единица в языке С++. Стейтмент в программировании — это то же самое, что и «предложение» в русском языке. Мы пишем предложения, чтобы выразить какую-то идею. В языке C++ мы пишем стейтменты, чтобы выполнить какое-то задание. Все стейтменты в языке C++ заканчиваются точкой с запятой.
Есть много разных видов стейтментов в языке C++. Рассмотрим самые распространенные из них:
|
|
|
int x; x = 5; std::cout << x; |
|
int х — это стейтмент объявления (англ. «statement declaration»). Он сообщает компилятору, что х является переменной. В программировании каждая переменная занимает определенное число адресуемых ячеек в памяти в зависимости от её типа. Минимальная адресуемая ячейка — байт. Переменная типа int может занимать до 4 байт, т.е. до 4 адресуемых ячеек памяти. Все переменные в программе должны быть объявлены, прежде чем использованы. Мы детально поговорим о переменных на следующих уроках.
х = 5 — это стейтмент присваивания (англ. «assignment statement»). Здесь мы присваиваем значение 5 переменной х.
std::cout << x; — это стейтмент вывода (англ. «output statement»). Мы выводим значение переменной х на экран.
Выражения
Компилятор также способен обрабатывать выражения. Выражение (англ. «expression») — это математический объект, который создается (составляется) для проведения вычислений и нахождения соответствующего результата. Например, в математике выражение 2 + 3 имеет значение 5. Выражения в языке С++ могут содержать:
отдельные цифры и числа (например, 2, 45);
буквенные переменные (например, х, у);
операторы, в т.ч. математические (например, +, -);
функции.
Выражения могут состоять как из единичных символов — цифр или букв (например, 2 или х), так и из различных комбинаций этих символов с операторами (например, 2 + 3, 2 + х, х + у или (2 + х) * (y - 3)). Для наглядности разберем простой корректный стейтмент присваивания х = 2 + 3;. Здесь мы вычисляем результат сложения чисел 2 + 3, который затем присваиваем переменной х.
Функции
В языке C++ стейтменты объединяются в блоки — функции. Функция — это последовательность стейтментов. Каждая программа, написанная на языке C++, должна содержать главную функцию main(). Именно с первого стейтмента, находящегося в функции main(), и начинается выполнение всей программы. Функции, как правило, выполняют конкретное задание. Например, функция max() может содержать стейтменты, которые определяют большее из заданных чисел, а функция calculateGrade() может вычислять среднюю оценку студента по какой-либо дисциплине.
Совет: Всегда размещайте функцию main() в файле .cpp с именем, совпадающим с именем проекта. Например, если вы пишете программу Chess, то поместите вашу функцию main() в файл chess.cpp.
Библиотеки
Библиотека — это набор скомпилированного кода (например, функций), который был «упакован» для повторного использования в других программах. С помощью библиотек можно расширить возможности программ. Например, если вы пишете игру, то вам придется подключать библиотеки звука или графики (если вы самостоятельно не хотите их создавать).
Язык C++ не такой уж и большой, как вы могли бы подумать. Тем не менее, он идет в комплекте со Стандартной библиотекой С++, которая предоставляет дополнительный функционал. Одной из наиболее часто используемых частей Стандартной библиотеки C++ является библиотека iostream, которая позволяет выводить данные на экран и обрабатывать пользовательский ввод.
Пример простой программы
Теперь, когда у вас есть общее представление о том, что такое стейтменты, функции и библиотеки, давайте рассмотрим еще раз программу «Hello, world!»:
#include <iostream>
int main()
{
std::cout << "Hello, world!";
return 0;
}
Строка №1: Специальный тип инструкции, который называется директивой препроцессора. Директивы препроцессора сообщают компилятору, что ему нужно выполнить определенное задание. В этом случае мы говорим компилятору, что хотели бы подключить содержимое заголовочного файла <iostream> к нашей программе. Подключение заголовочного файла <iostream> дает нам возможность использовать функционал библиотеки iostream, что, в свою очередь, позволяет выводить нам данные на экран.
Строка №2: Пустое пространство, которое игнорируется компилятором.
Строка №3: Объявление главной функции main().
Строки №4 и №7: Указываем компилятору область функции main(). Всё, что находится между открывающей фигурной скобкой в строке №4 и закрывающей фигурной скобкой в строке №7 — считается содержимым функции main().
Строка №5: Наш первый стейтмент (заканчивается точкой с запятой) — стейтмент вывода. std::cout — это специальный объект, используя который мы можем выводить данные на экран. << — это оператор вывода. Всё, что мы отправляем в std::cout, — выводится на экран. В этом случае, мы выводим текст "Hello, world!".
Строка №6: Оператор возврата return. Когда программа завершает свое выполнение, функция main() передает обратно в операционную систему значение, которое указывает на результат выполнения программы: успешно ли прошло выполнение программы или нет.
Если оператор return возвращает число 0, то это значит, что всё хорошо! Ненулевые возвращаемые значения указывают на то, что что-то пошло не так и выполнение программы было прервано. Об операторе return мы еще поговорим детально на соответствующем уроке.
Синтаксис и синтаксические ошибки
Как вы, должно быть, знаете, в русском языке все предложения подчиняются правилам грамматики. Например, каждое предложение должно заканчиваться точкой. Правила, которые регулируют построение предложений, называются синтаксисом. Если вы не поставили точку и записали два предложения подряд, то это является нарушением синтаксиса русского языка.
Язык C++ также имеет свой синтаксис: правила написания кода/программ. При компиляции вашей программы, компилятор отвечает за то, чтобы ваша программа соответствовала правилам синтаксиса языка C++. Если вы нарушили правила, то компилятор будет ругаться и выдаст вам ошибку.
Например, давайте посмотрим, что произойдет, если мы не укажем в конце стейтмента точку с запятой:
|
|
|
#include <iostream> int main() { std::cout << "Hello world!" return 0; } |
|
Результат:
E0065: требуется точка с запятой ";"
C2143: синтаксическая ошибка: отсутствие ";" перед "}"
Допущена синтаксическая ошибка в строке №6: мы забыли указать точку с запятой перед оператором return. В этом случае ошибка на самом деле в конце строки №5. В большинстве случаев компилятор правильно определяет строку с ошибкой, но есть ситуации, когда ошибка не заметна вплоть до начала следующей строки.
Синтаксические ошибки нередко совершаются при написании программ. К счастью, большинство из них можно легко найти и исправить. Но следует помнить, что программа может быть полностью скомпилирована и выполнена только при отсутствии ошибок.
Комментарий — это строка (или несколько строк) текста, которая вставляется в исходный код для объяснения того, что делает код. В языке C++ есть 2 типа комментариев: однострочные и многострочные.
Однострочные комментарии
Однострочные комментарии — это комментарии, которые пишутся после символов //. Они пишутся в отдельных строках и всё, что находится после этих символов комментирования, — игнорируется компилятором, например:
|
std::cout << «Hello, world!» << std::endl; // всё, что находится справа от двойного слеша, - игнорируется компилятором |
|
Как правило, однострочные комментарии используются для объяснения одной строчки кода:
|
std::cout << «Hello, world!» << std::endl; // cout и endl находятся в библиотеке iostream std::cout << «It is so exciting!» << std::endl; // эти комментарии усложняют чтение кода std::cout << «Yeah!» << std::endl; // особенно, когда строки разной длины |
|
Размещая комментарии справа от кода, мы затрудняем себе как чтение кода, так и чтение комментариев. Следовательно, однострочные комментарии лучше размещать над строками кода:
|
|
|
// cout и endl находятся в библиотеке iostream std::cout << «Hello, world!» << std::endl;
// теперь уже легче читать std::cout << «It is so exciting!» << std::endl;
// не так ли? std::cout << «Yeah!» << std::endl; |
|
Многострочные комментарии
Многострочные комментарии — это комментарии, которые пишутся между символами /* */. Всё, что находится между звёздочками, — игнорируется компилятором:
|
|
|
/* Это многострочный комментарий. Эта строка игнорируется и эта тоже. */ |
|
Так как всё, что находится между звёздочками, — игнорируется, то иногда вы можете наблюдать следующее:
|
|
|
/* Это многострочный комментарий. * Звёздочки слева * упрощают чтение текста */ |
|
Многострочные комментарии не могут быть вложенными (т.е. одни комментарии внутри других):
/* Это многострочный /* комментарий */ а это уже не комментарий */
// Верхний комментарий заканчивается перед первым */, а не перед вторым */
Переменные
Cтейтмент a = 8; выглядит довольно простым: мы присваиваем значение 8 переменной a. Но что такое a? a — это переменная, объект с именем.
На этом уроке мы рассмотрим только целочисленные переменные. Целое число — это число, которое можно записать без дроби, например: -11, -2, 0, 5 или 34.
Для создания переменной используется стейтмент объявления (разницу между объявлением и определением переменной мы рассмотрим несколько позже). Вот пример объявления целочисленной переменной a (которая может содержать только целые числа):
|
|
|
int a; |
|
При выполнении этой инструкции центральным процессором часть оперативной памяти выделяется под этот объект. Например, предположим, что переменной a присваивается ячейка памяти под номером 150. Когда программа видит переменную a в выражении или в стейтменте, то она понимает, что для того, чтобы получить значение этой переменной, нужно заглянуть в ячейку памяти под номером 150.
Одной из наиболее распространенных операций с переменными является операция присваивания, например:
|
|
|
a = 8; |
|
Когда процессор выполняет эту инструкцию, он понимает её как «поместить значение 8 в ячейку памяти под номером 150».
Затем мы сможем вывести это значение на экран с помощью std::cout:
|
std::cout << a; // выводим значение переменной a (ячейка памяти под номером 150) на экран |
|
l-values и r-values
В языке C++ все переменные являются l-values. l-value (в переводе «л-значение», произносится как «ел-валью») — это значение, которое имеет свой собственный адрес в памяти. Поскольку все переменные имеют адреса, то они все являются l-values (например, переменные a, b, c — все они являются l-values). l от слова «left», так как только значения l-values могут находиться в левой стороне в операциях присваивания (в противном случае, мы получим ошибку). Например, стейтмент 9 = 10; вызовет ошибку компилятора, так как 9 не является l-value. Число 9 не имеет своего адреса в памяти и, таким образом, мы ничего не можем ему присвоить (9 = 9 и ничего здесь не изменить).
Противоположностью l-value является r-value (в переводе «р-значение», произносится как «ер-валью»). r-value — это значение, которое не имеет постоянного адреса в памяти. Примерами могут быть единичные числа (например, 7, которое имеет значение 7) или выражения (например, 3 + х, которое имеет значение х плюс 3).
Вот несколько примеров операций присваивания с использованием r-values:
|
int a; // объявляем целочисленную переменную a a = 5; // 5 имеет значение 5, которое затем присваивается переменной а a = 4 + 6; // 4 + 6 имеет значение 10, которое затем присваивается переменной а
int b; // объявляем целочисленную переменную b b = a; // a имеет значение 10 (исходя из предыдущих операций), которое затем присваивается переменной b b = b; // b имеет значение 10, которое затем присваивается переменной b (ничего не происходит) b = b + 2; // b + 2 имеет значение 12, которое затем присваивается переменной b |
|
Давайте детально рассмотрим последнюю операцию присваивания:
|
|
|
b = b + 2; |
|
Здесь переменная b используется в двух различных контекстах. Слева b используется как l-value (переменная с адресом в памяти), а справа b используется как r-value и имеет отдельное значение (в данном случае, 12). При выполнении этого стейтмента, компилятор видит следующее:
|
|
|
b = 10 + 2; |
|
И здесь уже понятно, какое значение присваивается переменной b.
Сильно беспокоиться о l-values или r-values сейчас не нужно, так как мы еще вернемся к этой теме на следующих уроках. Всё, что вам нужно сейчас запомнить — это то, что в левой стороне операции присваивания всегда должно находиться l-value (которое имеет свой собственный адрес в памяти), а в правой стороне операции присваивания — r-value (которое имеет какое-то значение).
Инициализация vs. Присваивание
В языке C++ есть две похожие концепции, которые новички часто путают: присваивание и инициализация.
После объявления переменной, ей можно присвоить значение с помощью оператора присваивания (знак равенства =):
|
|
|
int a; // это объявление переменной a = 8; // а это присваивание переменной a значения 8 |
|
В языке C++ вы можете объявить переменную и присвоить ей значение одновременно. Это называется инициализацией (или «определением»).
|
|
|
int a = 8; // инициализируем переменную a значением 8 |
|
Переменная может быть инициализирована только после операции объявления.
Хотя эти два понятия близки по своей сути и часто могут использоваться для достижения одних и тех же целей, все же в некоторых случаях следует использовать инициализацию, вместо присваивания, а в некоторых — присваивание вместо инициализации.
Правило: Если у вас изначально имеется значение для переменной, то используйте инициализацию, вместо присваивания.
Неинициализированные переменные
В отличие от других языков программирования, языки Cи и C++ не инициализируют переменные определенными значениями (например, нулем) по умолчанию. Поэтому, при создании переменной, ей присваивается ячейка в памяти, в которой уже может находиться какой-нибудь мусор! Переменная без значения (со стороны программиста или пользователя) называется неинициализированной переменной.
Использование неинициализированных переменных может привести к ошибкам, например:
|
#include <iostream>
int main() { // Объявляем целочисленную переменную a int a;
// Выводим значение переменной a на экран (a - это неинициализированная переменная) std::cout << a;
return 0; } |
|
В этом случае компилятор присваивает переменной a ячейку в памяти, которая в данный момент свободна (не используется). Затем значение переменной a отправляется на вывод. Но что мы увидим на экране? Ничего, так как компилятор это не пропустит — выведется ошибка, что переменная a является неинициализированной. В более старых версиях Visual Studio компилятор вообще мог бы вывести какое-то некорректное значение (например, 7177728, т.е. мусор), которое было бы содержимым той ячейки памяти, которую он присвоил нашей переменной.
Использование неинициализированных переменных является одной из самых распространенных ошибок начинающих программистов, но, к счастью, большинство современных компиляторов выдадут ошибку во время компиляции, если обнаружат неинициализированную переменную.
Хорошей практикой считается всегда инициализировать свои переменные. Это будет гарантией того, что ваша переменная всегда имеет определенное значение и вы не получите ошибку от компилятора.
Адреса и переменные
Как вы уже знаете, переменные — это имена кусочков памяти, которые могут хранить информацию. Помним, что компьютеры имеют оперативную память, которая доступна программам для использования. Когда мы определяем переменную, часть этой памяти отводится ей.
Наименьшая единица памяти — бит (англ. «bit« от «binary digit»), который может содержать либо значение 0, либо значение 1. Вы можете думать о бите, как о переключателе света — либо свет выключен (0), либо включен (1). Чего-то среднего между ними нет. Если просмотреть случайный кусочек памяти, то всё, что вы увидите, — будет ...011010100101010... или что-то в этом роде. Память организована в последовательные части, каждая из которых имеет свой адрес. Подобно тому, как мы используем адреса в реальной жизни, чтобы найти определенный дом на улице, так и здесь: адреса позволяют найти и получить доступ к содержимому, которое находится в определенном месте памяти. Возможно, это удивит вас, но в современных компьютерах, у каждого бита по отдельности нет своего собственного адреса. Наименьшей единицей с адресом является байт (который состоит из 8 битов).
Поскольку все данные компьютера — это лишь последовательность битов, то мы используем тип данных (или просто «тип»), чтобы сообщить компилятору, как интерпретировать содержимое памяти. Вы уже видели пример типа данных: int (целочисленный тип данных). Когда мы объявляем целочисленную переменную, то мы сообщаем компилятору, что «кусочек памяти, который находится по такому-то адресу, следует интерпретировать как целое число».
Когда вы указываете тип данных для переменной, то компилятор и процессор заботятся о деталях преобразования вашего значения в соответствующую последовательность бит определенного типа данных. Когда вы просите ваше значение обратно, то оно «восстанавливается» из этой же последовательности бит.
Кроме int, есть много других типов данных в языке C++, большинство из которых мы детально рассмотрим на соответствующих уроках.
Фундаментальные типы данных в С++
В языке C++ есть встроенная поддержка определенных типов данных. Их называют основными типами данных (или «фундаментальные/базовые/встроенные типы данных»).
Вот список основных типов данных в языке C++:
|
Категория |
Тип |
Значение |
Пример |
|
Логический тип данных |
bool |
true или false |
true |
|
Символьный тип данных |
char, wchar_t, char16_t, char32_t |
Один из ASCII-символов |
‘c’ |
|
Тип данных с плавающей запятой |
float, double, long double |
Десятичная дробь |
3.14159 |
|
Целочисленный тип данных |
short, int, long, long long |
Целое число |
64 |
|
Пустота |
void |
Пустота |
Объявление переменных
Вы уже знаете, как объявить целочисленную переменную:
|
|
|
int nVarName; // int - это тип, а nVarName - это имя переменной |
|
Принцип объявления переменных других типов аналогичен:
|
type varName; // type - это тип (например, int), а varName - это имя переменной |
|
Объявление пяти переменных разных типов:
|
|
|
bool bValue; char chValue; int nValue; float fValue; double dValue; |
|
Обратите внимание, переменной типа void здесь нет (о типе void мы поговорим детально на следующем уроке).
|
void vValue; // не будет работать, так как void не может использоваться в качестве типа переменной |
|
Инициализация переменных
При объявлении переменной мы можем присвоить ей значение в этот же момент. Это называется инициализацией переменной.
Язык C++ поддерживает 2 основных способа инициализации переменных.
Способ №1: Копирующая инициализация (или «инициализация копированием») с помощью знака равенства =:
|
int nValue = 5; // копирующая инициализация |
|
Способ №2: Прямая инициализация с помощью круглых скобок ():
|
int nValue(5); // прямая инициализация |
|
Прямая инициализация лучше работает с одними типами данных, копирующая инициализация — с другими.
uniform-инициализация
Прямая или копирующая инициализация работают не со всеми типами данных (например, вы не сможете использовать эти способы для инициализации списка значений).
В попытке обеспечить единый механизм инициализации, который будет работать со всеми типами данных, в C++11 добавили новый способ инициализации, который называется uniform-инициализация:
|
|
|
int value{5}; |
|
Инициализация переменной с пустыми фигурными скобками указывает на инициализацию по умолчанию (переменной присваивается 0):
|
int value{}; // инициализация переменной по умолчанию значением 0 (ноль) |
|
В uniform-инициализации есть еще одно дополнительное преимущество: вы не сможете присвоить переменной значение, которое не поддерживает её тип данных — компилятор выдаст предупреждение или сообщение об ошибке. Например:
|
int value{4.5}; // ошибка: целочисленная переменная не может содержать нецелочисленные значения |
|
Правило: Используйте uniform-инициализацию.
Присваивание переменных
Когда переменной присваивается значение после её объявления (не в момент объявления), то это копирующее присваивание (или просто «присваивание»):
|
int nValue; nValue = 5; // копирующее присваивание |
|
В языке C++ нет встроенной поддержки способов прямого/uniform-присваивания, есть только копирующее присваивание.
Объявление нескольких переменных
В одном стейтменте можно объявить сразу несколько переменных одного и того же типа данных, разделяя их имена запятыми. Например, следующие 2 фрагмента кода выполняют одно и то же:
|
|
|
int a, b; |
|
И:
|
|
|
int a; int b; |
|
Кроме того, вы даже можете инициализировать несколько переменных в одной строке:
|
|
|
int a = 5, b = 6; int c(7), d(8); int e{9}, f{10}; |
|
Есть 3 ошибки, которые совершают новички при объявлении нескольких переменных в одном стейтменте:
Ошибка №1: Указание каждой переменной одного и того же типа данных при инициализации нескольких переменных в одном стейтменте. Это не критичная ошибка, так как компилятор легко её обнаружит и сообщит вам об этом:
|
int a, int b; // неправильно (ошибка компиляции) int a, b; // правильно |
|
Ошибка №2: Использование разных типов данных в одном стейтменте. Переменные разных типов должны быть объявлены в разных стейтментах. Эту ошибку компилятор также легко обнаружит:
|
int a, double b; // неправильно (ошибка компиляции) int a; double b; // правильно (но не рекомендуется) // Правильно и рекомендуется (+ читабельнее) int a; double b; |
|
Ошибка №3: Инициализация двух переменных с помощью одной операции:
|
int a, b = 5; // неправильно (переменная a остаётся неинициализированной) int a = 5, b = 5; // правильно |
|
Хороший способ запомнить эту ошибку и не допускать в будущем — использовать прямую или uniform-инициализацию:
|
int a, b(5); int c, d{5}; |
|
Этот вариант наглядно показывает, что значение 5 присваивается только переменным b и d.
Так как инициализация нескольких переменных в одной строке является отличным поводом для совершения ошибок, то я рекомендую определять несколько переменных в одной строке только в том случае, если вы будете каждую из них инициализировать.
Объект std::cout
Как мы уже говорили на предыдущих уроках, объект std::cout (который находится в библиотеке iostream) используется для вывода данных на экран (в консольное окно). В качестве напоминания, вот наша программа «Hello, world!»:
|
|
|
#include <iostream> int main() { std::cout << "Hello, world!"; return 0; } |
|
Для вывода нескольких предложений на одной строке оператор вывода << нужно использовать несколько раз, например:
|
|
|
#include <iostream>
int main() { int a = 7; std::cout << "a is " << a; return 0; } |
|
Программа выведет:
a is 7
А какой результат выполнения следующей программы?
|
|
|
#include <iostream>
int main() { std::cout << "Hi!"; std::cout << "My name is Anton."; return 0; } |
|
Возможно, вы удивитесь, но:
Hi!My name is Anton.
Объект std::endl
Если текст нужно вывести раздельно (на нескольких строках) — используйте std::endl. При использовании с std::cout, std::endl вставляет символ новой строки. Таким образом, мы перемещаемся к началу следующей строки, например:
|
|
|
#include <iostream>
int main() { std::cout << "Hi!" << std::endl; std::cout << "My name is Anton." << std::endl; return 0; } |
|
Результат:
Hi!
My name is Anton.
Объект std::cin
std::cin является противоположностью std::cout. В то время как std::cout выводит данные в консоль с помощью оператора вывода <<, std::cin получает данные от пользователя с помощью оператора ввода >>. Используя std::cin мы можем получать и обрабатывать пользовательский ввод:
|
#include <iostream>
int main() { std::cout << "Enter a number: "; // просим пользователя ввести любое число int a = 0; std::cin >> a; // получаем пользовательское число и сохраняем его в переменную a std::cout << "You entered " << a << std::endl; return 0; } |
|
Попробуйте скомпилировать и запустить эту программу. При запуске вы увидите Enter a number:, а затем программа будет ждать, пока вы укажите число. Как только вы это сделаете и нажмете Enter, программа выведет You entered, а затем ваше число.
Например (я ввел 7):
Enter a number: 7
You entered 7
Это самый простой способ получения данных от пользователя. Мы будем его использовать в дальнейших примерах.
Если же ввести действительно большое число, то вы получите переполнение, так как переменная а может содержать числа только определенного размера/диапазона. Если число больше/меньше допустимых максимумов/минимумов, то происходит переполнение. Об этом мы детально поговорим на следующих уроках.
std::cin, std::cout, << и >>
Новички часто путают std::cin с std::cout и << с >>. Вот простые способы запомнить их различия:
std::cin и std::cout всегда находятся в левой стороне стейтмента;
std::cout используется для вывода значения (cOUT = вывод);
std::cin используется для получения значения (cIN = ввод);
оператор вывода << используется с std::cout и показывает направление, в котором данные движутся от r-value в консоль. std::cout << 7; (значение 7 перемещается в консоль);
оператор ввода >> используется с std::cin и показывает направление, в котором данные движутся из консоли в переменную. std::cin >> a; (значение из консоли перемещается в переменную a).